Formation BioAtlas is a 0–1 design initiative exploring how AI can support expert reasoning in drug opportunity evaluation. Teams were making high-stakes decisions with limited time and fragmented data spread across multiple systems, causing important opportunities to fall through the cracks.
I led research, design vision, and the execution of our MVP that helps experts compare, synthesize, and rapidly form insights without automating decisions or oversimplifying scientific nuance.
Atlas
Design Lead (me)
Product Manager
Director of Product
Engineers (3)
TeamTimeline6 months
The Problem
When evaluation depends on manual synthesis across tools, decision-making slows and promising opportunities fall through the cracks.
Reviewing details of an opportunity was incredibly labor intensive
Users had to manually open and search through sources. Often having hundreds of tabs open, switching from one to another.
This made tradeoffs difficult to compare and easy to lose over time.
Judgment decisions lived in people’s heads, or in random files and folders, not in systems
There was no true system of record or CRM for drug evaluation.
Past decisions, assumptions, and rationale were rarely captured in an accessible structured way.
As a result, teams repeatedly re-evaluated the same questions without shared context.


Teams needed AI support for triage, not automated answers that missed half the expert context
Scoring and automation almost always majorly flattened scientific nuance.
Experts need AI to enhance their agency not “insights” that rely on assumptions.

Want to learn more about the vision?
Dig into how the vision project helped us explore and align on where we wanted to go
How might we help experts analyze drug opportunities quickly without oversimplifying scientific nuance?
Research
We were designing a system that didn’t yet exist, not improving an existing workflow. To do that, we needed to understand how experts actually evaluated drug opportunities today; what tools they used, how they moved between them, where they took shortcuts, and where manual work slowed them down.
Because expert workflows varied widely and priorities shifted depending on context, we couldn’t rely on stated needs alone. Research was essential to uncover how experts sequenced information, how one answer informed the next, and which signals truly mattered in practice versus in theory.
Discovery interviews across roles and seniority
Card sorting to surface
mental models
Shadowing / workflow
observation
Card sorting to surface
mental models
-
Experts rarely evaluate a drug opportunity in isolation; judgment emerges through comparison across assets, prior decisions, and benchmarks. (which is usually reserved for later in the evaluation process)
Why this matters
Without easy comparison, experts relied on memory or external notes, slowing evaluation and increasing inconsistency. -
Despite varied workflows, experts consistently looked for the same core information early, using it to decide whether deeper evaluation was warranted.
Why it mattered
When these signals weren’t immediately accessible, experts spent time searching instead of reasoning. -
Experts moved through information dynamically, letting early answers determine what questions came next rather than following fixed flows.
Why it mattered
Rigid structures forced unnecessary steps and broke natural decision-making. -
Past judgments, what was considered, dismissed, and why, were often more valuable than raw data alone.
Why it mattered
When this context was lost, teams reworked the same decisions and missed how thinking had evolved. -
Workarounds and personal tools filled gaps in system support but obscured what was actually slowing teams down.
Why it mattered
Effort was spent maintaining process instead of evaluating opportunities, increasing the risk of missed insights.
Takeaways




From research to direction
1
Define the data foundation
2
Treat comparison as a dedicated workflow
3
Support judgment through layered information
4
Capture decisions and activity as data
5
Enable triage before deeper evaluation
1
Define the data foundation
Before Atlas could support evaluation, the right data needed to exist in the system. In parallel with interface design, I used research insights and early design mocks to identify and prioritize the minimum set of data required to support real user workflows.
This allowed our backend engineers to get started on data acquisition and integrations early, allowing us to test for quality, before we began building.
Meanwhile my PM and I collaborated on building out a CRM that users could use to start tracking opportunities. This allowed us to further understand what information was most important to our users and what opportunities we may still have for automation.

2
Treat comparison as a dedicated workflow
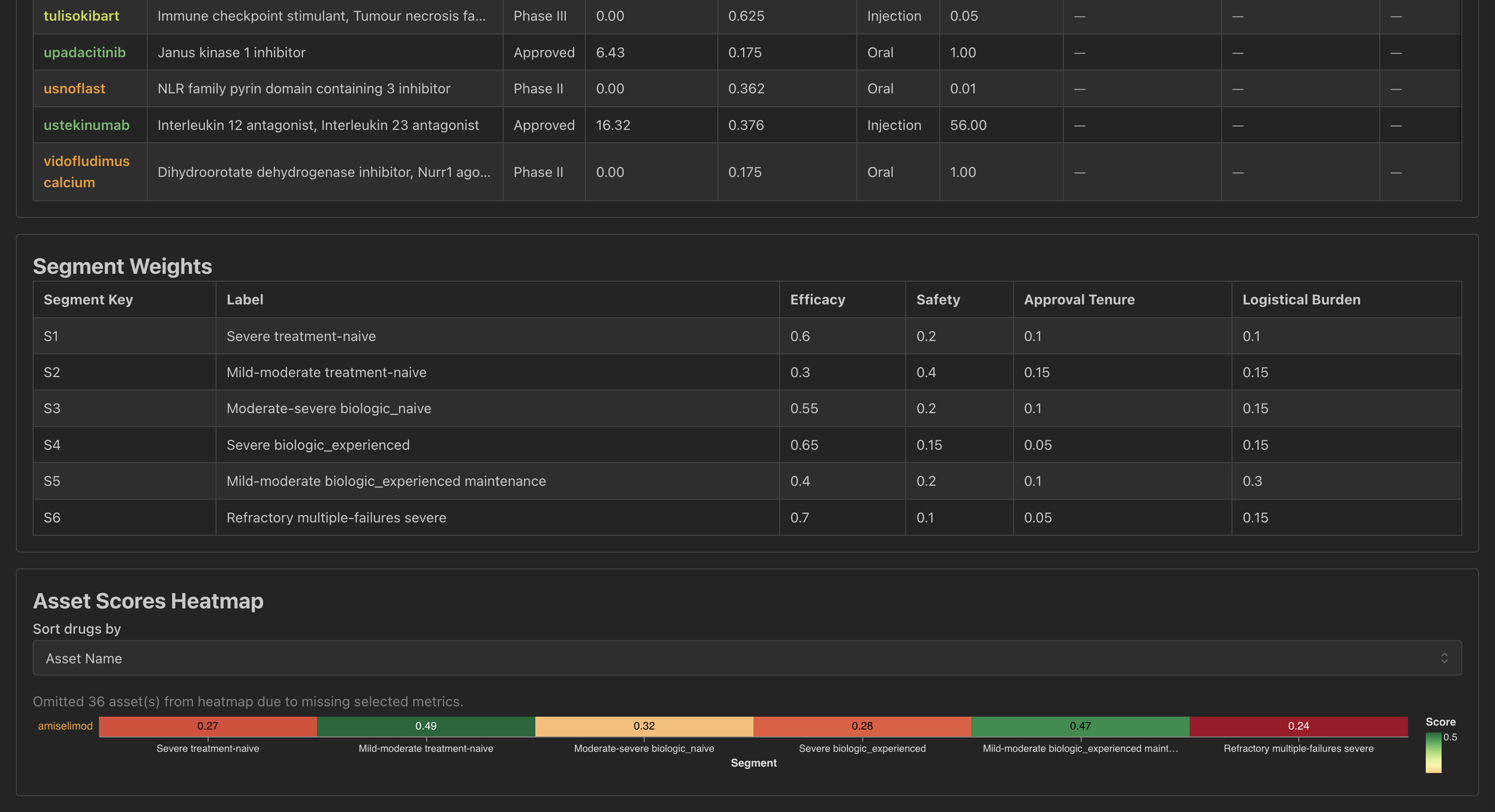
Research made it clear that evaluation is fundamentally comparative, but comparison required deeper data rigor and coordination than the initial MVP could support. Rather than forcing it into the early experience, we intentionally separated comparison into its own workflow.
This work is ongoing. I’m currently involved in defining testing methodologies and identifying where data accuracy and normalization are critical, with the goal of folding this workflow back into Atlas once the foundation is strong enough.
3
Support judgment through layered information
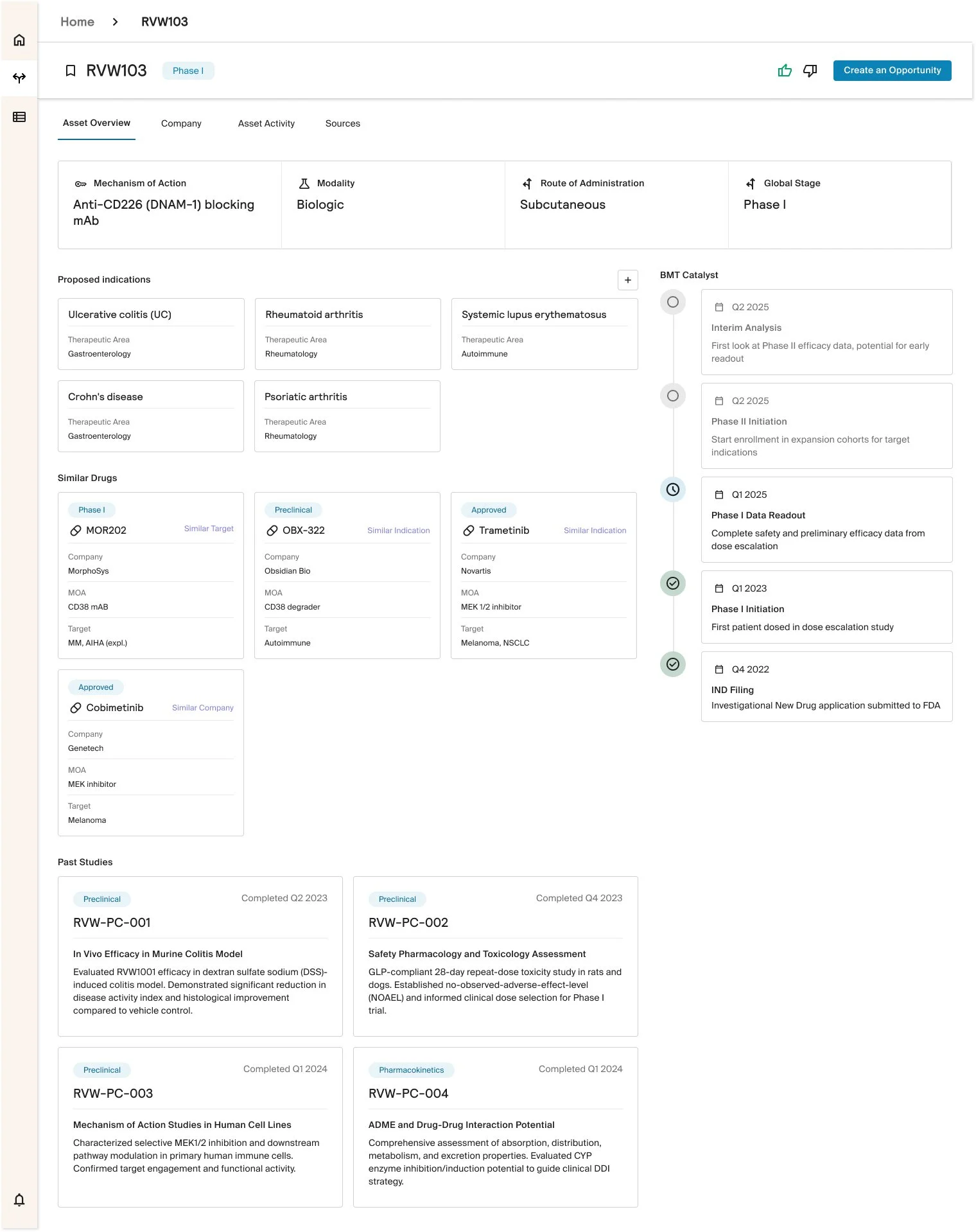
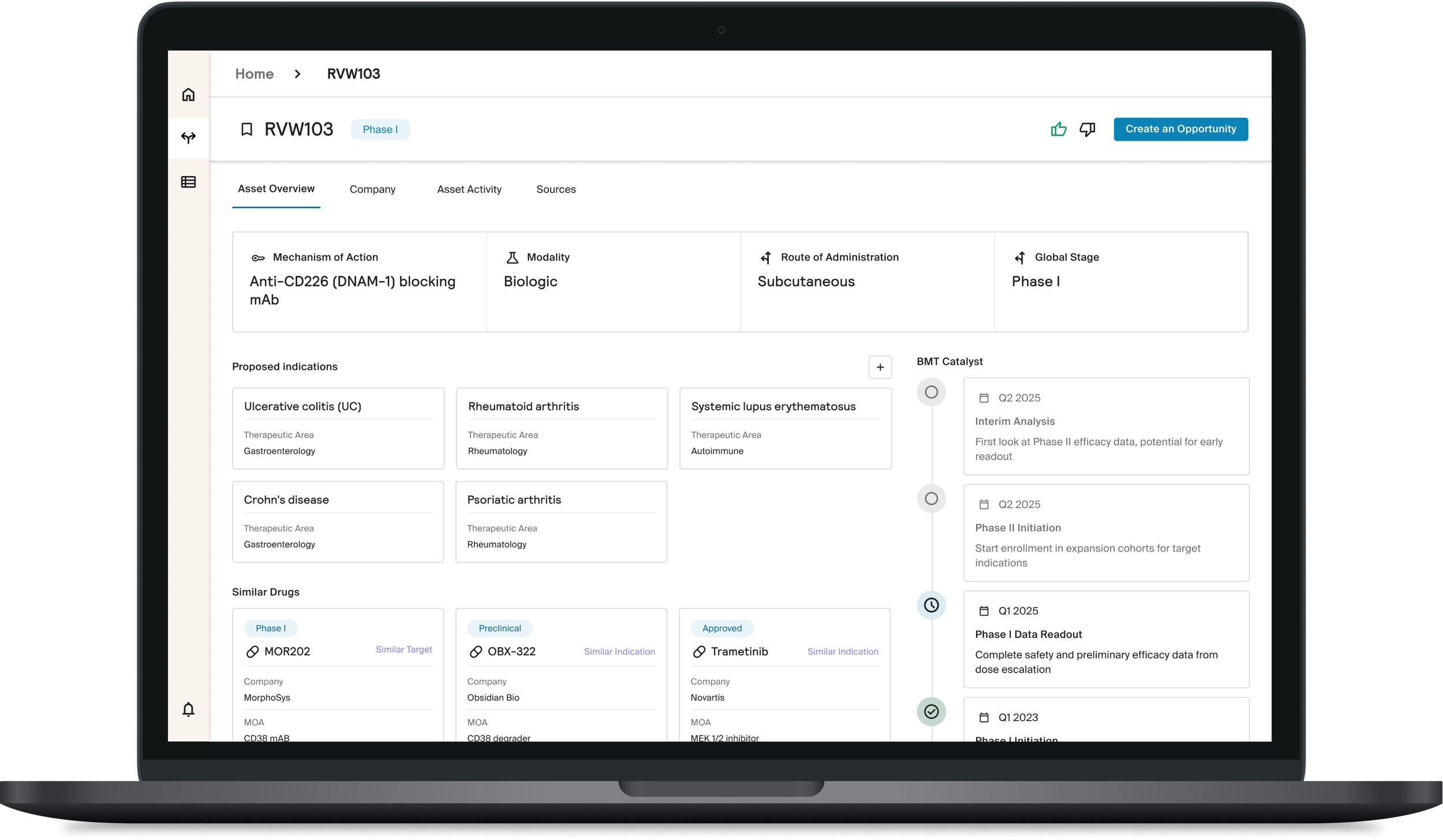
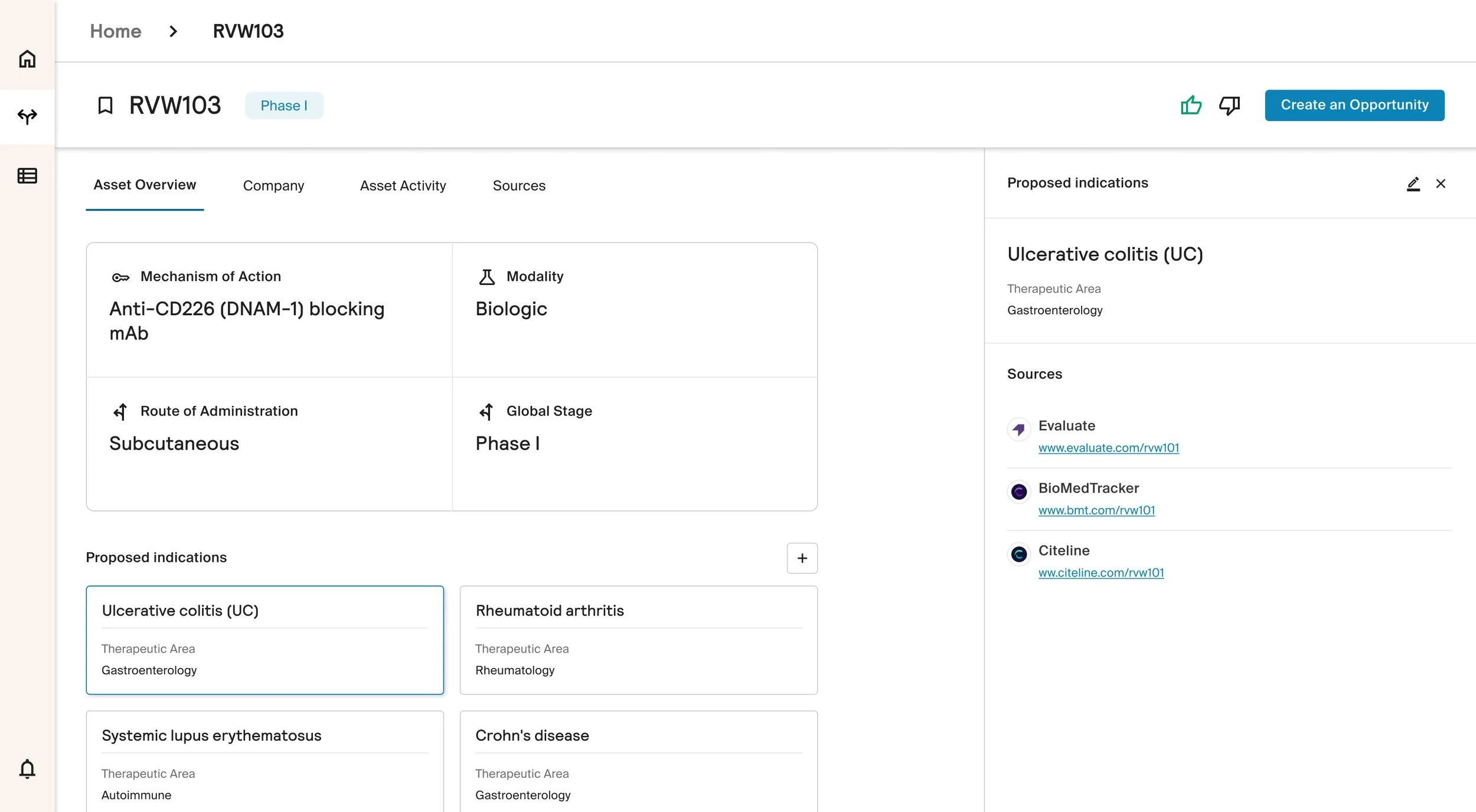
The interface pulls information from multiple sources, harmonizes it, and presents it in a skimmable, unified view. Users can search once and see what matters most upfront, with additional detail accessible through expandable panels when needed.
This approach supports quick judgment while preserving depth, allowing experts to control how much information they engage with at any moment.
4
Capture decisions and activity as data
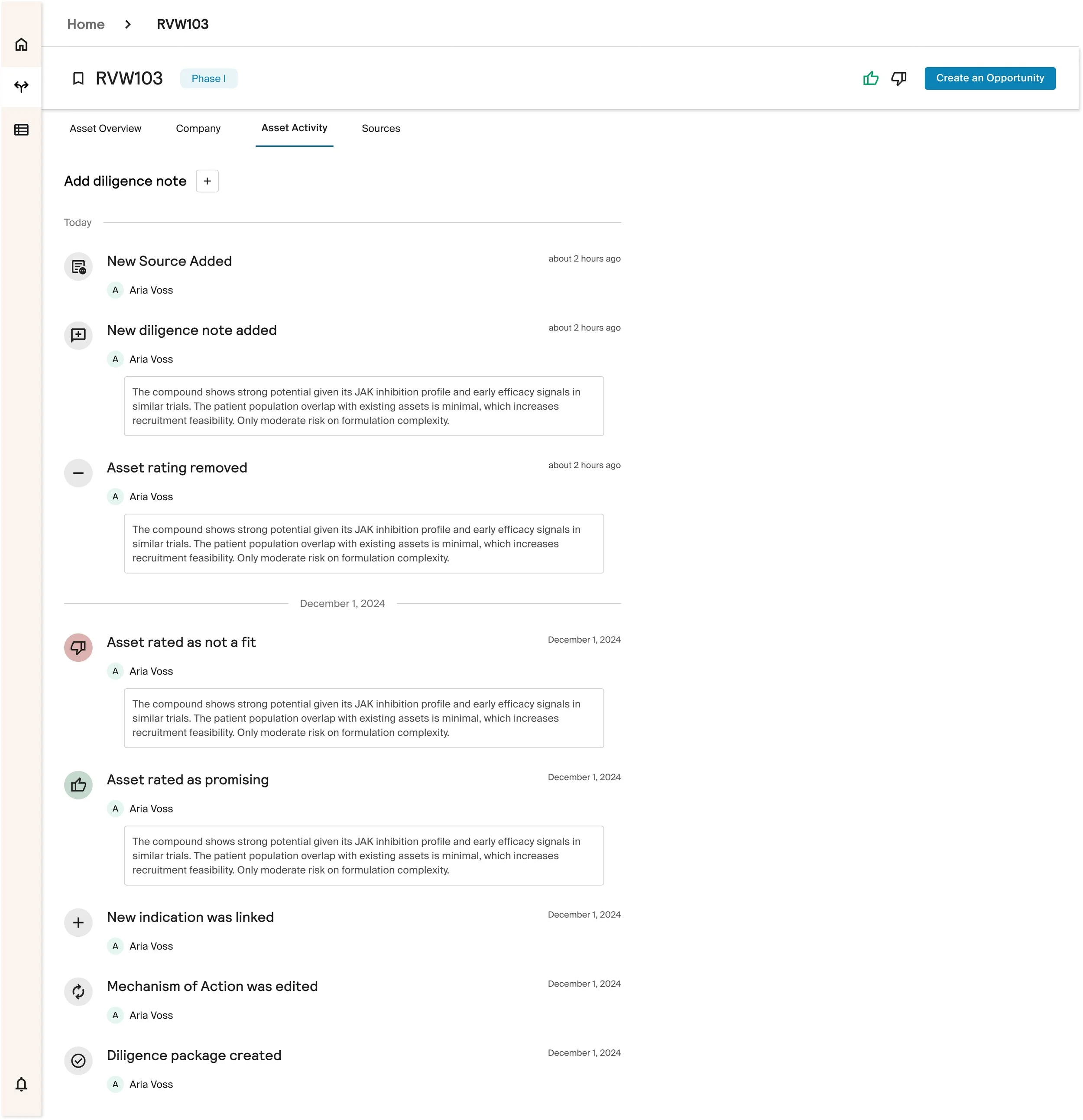
We designed systems to capture expert feedback and activity as part of the evaluation process. Comments, actions, and decisions are logged and surfaced as context, rather than living outside the system.
In parallel, the system tracks ongoing news and updates for each asset, proactively notifying users when major events occur, ensuring evaluations stay current without requiring constant manual checking.
5
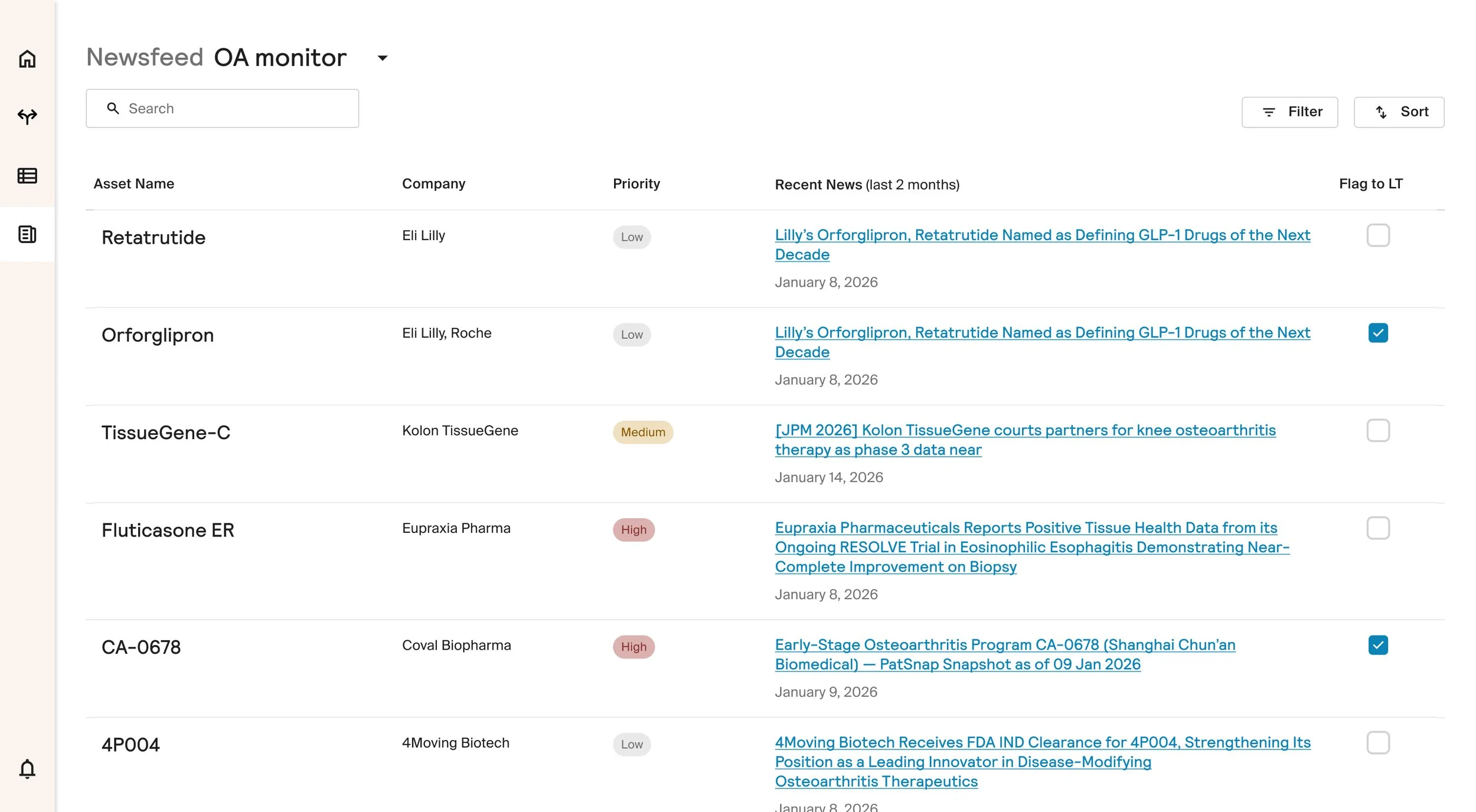
Enable triage before deeper evaluation
We designed systems to capture expert feedback and activity as part of the evaluation process. Comments, actions, and decisions are logged and surfaced as context, rather than living outside the system.
In parallel, the system tracks ongoing news and updates for each asset, proactively notifying users when major events occur, ensuring evaluations stay current without requiring constant manual checking.


What Shipped, and What’s Still Cooking
Delivered
-
Experts can search or upload existing datasets (e.g. CSVs) to quickly bring opportunities into the system.
-
Information from multiple sources is harmonized into a single view, making it easier to assess what matters most at a glance.
-
Deeper information is available through expandable panels, allowing experts to control depth without losing focus.
-
Comments, actions, and evaluations are logged as part of the workflow rather than living outside the system.
-
News and major updates are tracked and surfaced to help experts stay informed as assets evolve.
In progress
-
Comparison depends on high data accuracy and normalization. This work is ongoing, with active exploration of testing ux methodologies before fully integrating it into Atlas.
-
Additional data sources are being prioritized based on real usage patterns and core signals identified through research.
-
Early signals support fast evaluation today, with continued iteration planned as more decision data is captured.
-
As we learn more about user behavior, decision patterns, and data reliability, we’re exploring where AI can meaningfully support reasoning, without replacing expert judgment.
What this unlocks for usAtlas unlocks a shared foundation for expert reasoning, reducing manual work, preserving context, and making it easier for teams to evaluate opportunities without losing nuance. It also establishes a design-led approach to building internal systems, where data, judgment, and AI evolve together in response to real user needs.
What to learn more about the story?
•
Reach out!
•
What to learn more about the story? • Reach out! •